
Atualmente, nos deparamos com uma infinidade de dados, vindos das mais diversas fontes, que precisam ser analisados. Com isso, precisamos enfrentar o grande desafio que é integrar e processar estes dados para organizar toda a informação gerada por eles. Neste contexto entra um processo que, comumente, chamamos de ETL e que tem como principal objetivo a integração de dados gerados em diferentes fontes, extraindo-os, transformando-os e enviando-os para algum tipo de armazenamento.
Além do ETL, outra grande aliada na missão de processar este grande volume de dados gerados atualmente é a computação em nuvem, que disponibiliza recursos poderosos para a execução das tarefas necessárias.
Neste artigo, eu vou te apresentar o processo de ETL, assim como os recursos da plataforma de computação em nuvem da Google (GCP) que podem ser utilizados durante este processo.
Começando pelo início: O que é ETL?
O ETL é uma técnica que visa a integração de dados e surgiu quando foi identificada a necessidade de se agregar dados de diferentes fontes para que pudessem ser devidamente analisados. Essa sigla representa as três etapas que englobam o processo de integração de dados: Extração, Transformação e Carga (em inglês, respectivamente, Extraction, Transformation e Load).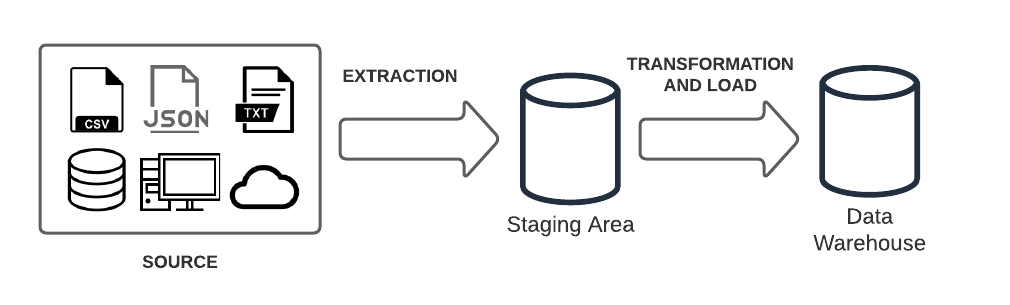
Imagem 01: Fluxograma geral de um processo de ETL.
+++ Extraction: Nesta etapa, os dados brutos (também conhecidos como raw data) são copiados das suas fontes (sejam estas estruturadas ou não estruturadas) para uma área temporária, conhecida como staging area, onde o processo de transformação ocorrerá.
+++ Transformation: Ocorrerá na staging area e será responsável por processar os dados brutos, transformando-os e consolidando-os para que possam ser utilizados corretamente em aplicações analíticas. Nesta etapa, é possível realizar as seguintes tarefas de tratamento de dados:
- Filtragem, limpeza, remoção de duplicatas, validações;
- Auditorias;
- Criptografia dos dados;
- Formatação dos dados em tabelas/unificação de tabelas para que estas correspondam ao schema do data warehouse alvo;
- Dentre muitos outros processos.
+++ Load: Agora, os dados (já transformados) são movidos da staging area para o data warehouse. Usualmente, este processo inicia com uma carga total dos dados da staging area e segue com cargas periódicas de modo que alterações sejam incluídas de modo incremental.
Cloud Computing – Uma grande aliada
Com essa colossal quantidade de dados para serem processados e analisados, notou-se a necessidade de maior poder computacional. É nesse contexto que a computação em nuvem (do inglês, Cloud Computing) ganha um papel fundamental durante a execução de todas as etapas de processamento de dados.
Além do custo-benefício, a computação em nuvem traz a grande vantagem de manter serviços altamente escaláveis conforme a demanda. Ou seja, é possível alocar mais recursos computacionais de maneira bastante prática e rápida quando necessário, assim como fazer o processo contrário.
Google Cloud Platform (GCP)
A Google Cloud Platform é a plataforma de computação em nuvem oferecida pela Google que oferece diversos serviços em nuvem para as mais diversas finalidades. Durante o nosso “Hands on”, logo mais, iremos utilizar alguns dos seus serviços e, por isso, achei interessante trazer um pouco de informações a respeito de cada um deles.
+++ Google Cloud Storage (GCS): é o serviço de armazenamento de dados da GCP e funciona como um repositório de arquivos dentro da infraestrutura da Google.
+++ BigQuery: um data warehouse completamente gerenciável e serverless presente na GCP. Trata-se de uma plataforma como serviço que suporta consultas utilizando ANSI SQL e permite análises de dados escalonáveis em petabytes. Além disso, possui recursos de machine learning integrados.
+++ Cloud Composer: versão do Apache Airflow (ferramenta de fluxo de trabalhos) hospedada na GCP. Ele é um serviço de orquestração de fluxo de trabalhos de dados completamente gerenciável que permite a criação, agendamento e monitoramento de pipelines.
Hands on
Para fins de demonstração de um processo de ETL completo, vamos utilizar a API do Spotify para recuperarmos as últimas 50 músicas reproduzidas pelo usuário e armazenar as informações das mesmas no BigQuery no final do processo. Todos os códigos utilizados nesta demonstração estão disponíveis neste link do GitHub.
Para realizarmos esta demonstração, será necessário ter acesso aos seguintes itens:
- Uma conta no spotify (premium ou gratuita);
- Uma conta no GCP (lembre-se, alguns recursos podem gerar custos).
1º Passo: Preparando tudo
+++ Criando uma conta de serviço na GCP:
- Para realizar a criação de uma conta de serviço, é necessário acessar a opção “IAM e administrador” no menu lateral do console da GCP. Na página seguinte, clique em “Contas de serviço”, no menu lateral.
- A seguir, clique no botão “CRIAR CONTA DE SERVIÇO”, no topo da página.
- Preencha as informações:
- Detalhes da conta de serviço: informe o nome que deseja dar à esta conta de serviço.
- Conceda acesso ao projeto para a conta de serviço. Certifique-se de ter adicionado o papel de leitor a esta conta de serviço.
+++ Fazendo download do Key File da conta de serviço:
- Entre na conta de serviço criada clicando no nome dela na lista de contas de serviço.
- A seguir, navegue até a aba “CHAVES”.
- Em seguida, clique em “Adicionar Chave → Criar Nova Chave”.
- Selecione o tipo de chave “JSON” e, então, clique em “Criar”.
- Um download será realizado para o seu computador.
- Renomeie o arquivo baixado para “key_file.json” e copie-o para a pasta raiz, onde iremos colocar nossos arquivos com os códigos desta demonstração.
+++ Crie um novo Bucket no GCS:
Acesse a opção “Cloud Storage” no menu lateral da GCP. Em seguida, clique em “Navegador”, no menu lateral esquerdo. Então, clique em “Criar intervalo”, no menu superior.
- Nomeie o Bucket:
Para esta demonstração, vamos nomear ele como “poc_etl”. - Escolha o local de armazenamento do bucket:
Marque a opção “Multi-region” e, em Local, selecione “us(várias regiões nos Estados Unidos)” - Escolha uma classe de armazenamento padrão para os dados:
Neste caso, vamos escolher a classe “Standard” - Escolha como controlar o acesso aos objetos;
Vamos escolher a opção “Detalhado”. - Configurações avançadas (opcional);
Não vamos mexer aqui. - Clique em “Criar”.
2º Passo: Extração
Nesta etapa, precisaremos escrever uma função em Python que fará a requisição à API do Spotify, que irá gerar um arquivo JSON com todas as informações referentes às últimas 50 (ou menos, caso o usuário não tenha ouvido este número de músicas nas últimas 24 horas). Toda a documentação da API do Spotify pode ser consultada neste link.
O primeiro passo, é gerar um Token para autorizar a consulta da API. Para isso, acesse este link, faça login na sua conta do Spotify (se solicitado). Desça até o final da página e, no campo OAuth Token, clique em “Generate Token”. No pop-up aberto, selecione o checkbox da opção “user-read-recently-played” e em seguida clique em “Request Token”. Você irá ver um Token no campo OAuth Token. Copie e guarde esta informação.
Com o Token copiado, vamos gerar um arquivo JSON para armazenar e, posteriormente, consultar esta informação. Crie um arquivo chamado “spotify_secret.json”, na raiz do seu diretório, obedecendo a seguinte formatação:
{
"token":"SEU_TOKEN_VAI_AQUI"
}
É importante lembrar que este Token expira após 15 minutos. Então, caso você receba um erro referente a validade deste Token, é necessário realizar o processo descrito acima de novo para renová-lo.
Agora podemos iniciar o código propriamente dito!
Na raiz do seu diretório, crie um novo arquivo em python chamado etl.py. Nele, iremos escrever todas as funções desta demonstração.
Primeiramente, iremos realizar todos os imports necessários:
import datetime import json import os import shutil import pandas as pd import requests from gcloud import storage from google.cloud import bigquery from google.cloud.exceptions import NotFound
Antes de começarmos a função de extração, precisamos criar duas funções auxiliares:
A primeira delas é a função responsável por ler o arquivo que contém o nosso token para a API do Spotify:
def read_spotify_secret(json_file_path: str) -> dict: """ Esta função realiza a leitura do arquivo JSON contendo o token da API e armazena-o em um dicionário :param str json_file_path: Caminho local para o arquivo JSON. :return: Retorna um dicionário contendo o token da API do Spotify. :rtype: dict """ with open(json_file_path) as jf: secrets = json.load(jf) return secrets
A segunda, vai ser a função responsável por fazer o upload do arquivo gerado pela extração (e depois pela transformação também) para o bucket no GCS que criamos mais cedo:
def upload_object_to_bucket(bucket_name: str, object_path: str, object_key=None) -> bool: """ Esta função é responsável por fazer upload de um arquivo/objeto a um determinado bucket no GCS. :param str bucket_name: Nome do bucket que receberá o arquivo/objeto. :param str object_path: Caminho local para o arquivo/objeto que será enviado ao bucket. :param str object_key: O caminho final do objeto dentro do bucket. Este parametro é opcional e caso não seja informado o valor do parametro object_path será assumido. :returns: True se o upload for bem sucedido. False caso contrário. :rtype: bool """ file_name = (object_path if (object_key==None) else object_key) try: # Criando uma variável de ambiente contendo o caminho para o arquivo "key_file.json" da conta de serviço pk_path = os.getcwd()+"\\key_file.json" os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = pk_path # Instanciando um novo cliente da API gcloud client = storage.Client() # Recuperando um objeto referente ao nosso Bucket bucket = client.get_bucket(bucket_name) if bucket==None: return False # Fazendo upload do objeto (arquivo) desejado blob = bucket.blob(file_name) blob.upload_from_filename(object_path) except Exception as e: print(e) return False except FileNotFoundError as e: print(e) return False return True
Agora, iremos construir a função responsável por extrair uma resposta da API de maneira bruta (também chamamos de raw). Vamos nos preocupar em refinar este material posteriormente, na etapa de transformação.
def extract_spotify_data(spotify_secret_file_path='', bucket_name='') -> str:
"""
Esta função é responsável pela extração dos dados do Spotify através de uma requisição à API.
:param str spotify_secret_file_path: Caminho local para o arquivo JSON contendo o token do Spotify.
:param str bucket_name: Nome do bucket que receberá o arquivo/objeto com os dados.
:return: Retorna o object_key (caminho para o objeto JSON dentro do bucket)
:rtype: str
"""
# Fazendo a leitura do token da API do Spotify e armazenando-o em uma variável
secrets = read_spotify_secret(spotify_secret_file_path)
token = secrets["token"]
# Definindo os headers para a requisição à API
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
# Definindo um limite de 24 horas antes do momento que a função for executada
# Com isso, conseguimos recuperar as últimas 50 músicas reproduzidas nas últimas 24 horas
today = datetime.datetime.now()
yesterday = today - datetime.timedelta(days=1) # Ontem = Hoje - 1 Dia
# Convertendo a data para o formato Unix Timestamp, que é o formato utilizado pela API
yesterdays_timestamp = int(yesterday.timestamp())*1000
# Realizando a requisição:
# O parâmetro "after" serve para indicarmos a partir de quando devemos fazer a busca
# O parâmetro "limit" define o limite de músicas retornadas (o valor máximo é 50)
request = requests.get(f"https://api.spotify.com/v1/me/player/recently-played?after={yesterdays_timestamp}&limit=50", headers = headers)
# Transformando o resultado da requisição em um objeto JSON
data = request.json()
# Recuperando a data e hora da execução
date = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# Checando a existência do diretório local para armazenar o JSON
if not os.path.exists('spotify_data\\raw\\'):
os.makedirs('spotify_data\\raw\\')
# Salvando o resultado da requisição em um arquivo JSON
file_name = f'spotify_data\\raw\\{date}_spotify_data.json'
with open(file_name, 'w+') as f:
json.dump(data, f, indent=4)
# Fazendo upload do arquivo JSON para o bucket
object_key = f"raw/{date}_spotify_data.json"
upload_object_to_bucket(bucket_name=bucket_name, object_path=file_name, object_key=object_key)
# Retorna o object key do objeto gerado (JSON com as músicas) dentro do bucket
full_object_key = f"{bucket_name}/{object_key}"
return full_object_key
Como resultado da execução desta função, teremos um novo arquivo em nosso bucket no diretório “raw/”, nomeado como “<data_hora>_spotify_data.json” além de termos como retorno o object key do nosso Objeto (basicamente, o caminho dentro do bucket).
Este arquivo possui todas as informações relacionadas às músicas encontradas pela requisição realizada na função de extração. Se você abrir o arquivo, vai ser possível verificar que existem muitas informações para cada música encontrada e, em alguns casos, muitas dessas informações são irrelevantes. É aí que entra a próxima etapa do ETL, a Transformação.
3º Passo: Transformação
Como já foi dito no spoiler do final do passo anterior, o arquivo gerado pela requisição que fizemos à API do Spotify possui inúmeros atributos e, no nosso caso, muitos deles são irrelevantes. Então, nada melhor que dar uma filtrada no conteúdo deste arquivo, mantendo apenas os atributos que nos interessamos!
Para esta demonstração, vamos imaginar que estamos interessados apenas nos seguintes atributos da músicas:
- Nome da música;
- Nome do álbum;
- Nome do artista;
- Duração da faixa;
- Popularidade da faixa;
- Data e hora de reprodução.
O nosso fluxo aqui basicamente vai ser o seguinte: a partir do object key gerado como resposta da nossa função de extração, vamos fazer download do JSON com os dados brutos que está no nosso bucket e, em seguida, vamos extrair as informações que queremos, salvando-as em um arquivo .csv que vai ser enviado para o mesmo bucket, mas dessa vez para o diretório “transformed/”.
def transform(json_object_key="") -> str:
"""
Esta função é responsavel pela transformação do arquivo JSON gerado pela função extract_spotify_data() em um arquivo .csv contendo apenas as informações desejadas.
:param str json_object_key: Caminho para o objeto dentro do bucket.
:return: Retorna o object_key (caminho para o objeto .csv dentro do bucket).
:rtype: str
"""
# Fazendo download do JSON do bucket, para iniciar as transformações
try:
# Criando uma variável de ambiente contendo o caminho para o arquivo "key_file.json" da conta de serviço
pk_path = os.getcwd()+"\\key_file.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = pk_path
# Instanciando um novo cliente da API gcloud
client = storage.Client()
# Variáveis auxiliares
full_object_key_splited = json_object_key.split('/')
bucket_name = full_object_key_splited[0]
object_key = json_object_key.replace(f"{bucket_name}/", "")
local_path = f"spotify_data//raw//{full_object_key_splited[-1]}"
# Criando um objeto para o Bucket
bucket = client.get_bucket(bucket_name)
# Criando um objeto BLOB para o caminho do arquivo
blob = bucket.blob(object_key)
# Fazendo download local do arquivo
blob.download_to_filename(local_path)
except Exception as e:
print(e)
exit()
# Abrindo o JSON que foi baixado
file = open(local_path)
data = json.load(file)
file.close()
# Definindo as listas que vão armazenar as informações que desejamos.
# Elas irão nos auxiliar a compor o Dataframe final que vai resultar num .csv.
song_names = []
album_names = []
artist_names = []
songs_duration_ms = []
songs_popularity = []
played_at_list = []
# Percorrendo todos os itens presentes no JSON e capturando as informações que
# queremos armazenar no .csv final
for song in data["items"]:
song_names.append(song["track"]["name"])
album_names.append(song["track"]["album"]["name"])
artist_names.append(song["track"]["album"]["artists"][0]["name"])
songs_duration_ms.append(song["track"]["duration_ms"])
songs_popularity.append(song["track"]["popularity"])
played_at_list.append(song["played_at"])
# Criando um dicionário com os resultados obtidos nas listas
song_dict = {
"song_name": song_names,
"album_name": album_names,
"artist_name": artist_names,
"duration_ms": songs_duration_ms,
"popularity": songs_popularity,
"played_at": played_at_list
}
# Transformando nosso dicionário em um dataframe
song_df = pd.DataFrame(song_dict, columns=["song_name", "album_name", "artist_name", "duration_ms", "popularity", "played_at"])
# Checando a existência do diretório local para armazenar o .csv
if not os.path.exists('spotify_data\\transformed\\'):
os.makedirs('spotify_data\\transformed\\')
# Convertendo nosso dataframe para um .csv
file_name = ((full_object_key_splited[-1]).rsplit('.',1)[0])+'.csv'
local_path = f"spotify_data\\transformed\\{file_name}"
song_df.to_csv(local_path, index=False)
# Fazendo upload do arquivo JSON para o bucket
object_key = f"transformed/{file_name}"
upload_object_to_bucket(bucket_name=bucket_name, object_path=local_path, object_key=object_key)
# Removendo os arquivos locais gerados
shutil.rmtree("spotify_data\\")
# Retorna o object key do objeto gerado (JSON com as músicas) dentro do bucket
full_object_key = f"{bucket_name}/{object_key}"
return full_object_key
Ao fim da execução desta função, teremos um arquivo .csv, nomeado como “<data_hora>_spotify_data.csv”, dentro do diretório “transformed/” em nosso bucket. Esse arquivo está pronto para ser consumido pelo BigQuery na nossa próxima etapa, a de carregamento (ou LOAD).
4º Passo: Carregamento ou Load
Esta é a última etapa do nosso processo de ETL. É aqui onde vamos pegar todos os dados que recuperamos através da requisição à API do Spotify no passo de Extração e transformamos selecionando apenas as informações que nos interessam no passo de Transformação para enviar à uma tabela no BigQuery.
A função de Load tem o seguinte fluxo: Primeiramente um novo Dataset chamado “Spotify_Data” será criado, caso ainda não exista. Após a criação do Dataset, ocorre a configuração do Job que será responsável pela leitura do arquivo .csv e inserção dos seus dados na tabela. O Job é, então executado e após ele realizamos a remoção dos dados duplicados (dados duplicados podem surgir neste exemplo, pois caso o ETL seja executado antes do usuário ouvir 50 músicas desde a última execução, alguns dados que apareceram no último .csv ainda estarão no novo arquivo gerado).
def load(csv_object_key="") -> bool:
"""
Esta é a função responsável por inserir todos os dados extraídos pela requisição à API do Spotify em uma tabela no Big Query.
:param str csv_object_key: Caminho para o objeto gerado pela função transform() dentro do bucket.
:return: True se a inserção tiver ocorrido com sucesso. False caso contrário.
:rtype: bool
"""
# Criando uma variável de ambiente contendo o caminho para o arquivo "key_file.json" da conta de serviço
pk_path = os.getcwd()+"\\key_file.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = pk_path
# Instanciando um novo cliente da API gcloud
client = bigquery.Client()
# Checa se o dataset existe. Se não existe, cria um novo dataset
dataset_id = "Spotify_Data"
try:
client.get_dataset(dataset_id)
print(f"O dataset {dataset_id} já existe!")
except NotFound:
try:
dataset = bigquery.Dataset(f"{client.project}.Spotify_Data")
client.create_dataset(dataset, timeout=30)
print(f"Dataset '{dataset_id}' criado com sucesso!")
except Exception as e:
print(e)
return False
try:
# Definindo nova tabela
table_id = f"{client.project}.{dataset_id}.recently_played"
destination_table = client.get_table(table_id)
# Definindo a configuração do Job
job_config = bigquery.LoadJobConfig(
# Definições do nosso schema (estrutura da tabela)
schema=[
bigquery.SchemaField("song_name", "STRING"),
bigquery.SchemaField("album_name", "STRING"),
bigquery.SchemaField("artist_name", "STRING"),
bigquery.SchemaField("duration_ms", "INTEGER"),
bigquery.SchemaField("popularity", "INTEGER"),
bigquery.SchemaField("played_at", "TIMESTAMP")
],
# Aqui definimos o número de linhas que queremos pular.
# Como a primeira linha do nosso csv contém o nome das colunas, queremos pular sempre 1 linha
skip_leading_rows = 1,
# Aqui definimos o formato do arquivo fonte (o nosso é um .csv)
source_format=bigquery.SourceFormat.CSV,
)
# Capturando o número de registros na tabela antes de iniciar o load
query_count = f"SELECT COUNT(*) FROM {table_id}"
query_count_job = client.query(query_count)
start_count = 0
for row in query_count_job:
start_count=start_count+row[0]
# Definimos a URI do nosso objeto .csv transformado dentro do bucket
uri = f"gs://{csv_object_key}"
# Iniciamos o job que vai carregar os dados para dentro da nossa tabela no BigQuery
load_job = client.load_table_from_uri(
uri, table_id, job_config=job_config
)
load_job.result()
# Removendo duplicatas
remove_duplicates_query = ( f"CREATE OR REPLACE TABLE {table_id}"
f" AS (SELECT DISTINCT * FROM {table_id})")
remove_duplicates_job = client.query(remove_duplicates_query)
remove_duplicates_job.result()
# Capturando o número de registros na tabela depois de realizar o load
query_count = f"SELECT COUNT(*) FROM {table_id}"
query_count_job = client.query(query_count)
end_count = 0
for row in query_count_job:
end_count=end_count+row[0]
print(f"{end_count-start_count} novos registros em {table_id}!")
except Exception as e:
print(e)
return False
return True
Esta é a última função necessária para concluirmos nosso fluxo ETL. Agora, para rodar todas elas, crie um arquivo chamado main.py no mesmo diretório do arquivo etl.py que contém as funções acima.
from etl import extract_spotify_data, transform, load if __name__=='__main__': json_path = extract_spotify_data(spotify_secret_file_path="spotify_secret.json", bucket_name="poc_etl") transformation = transform(json_object_key=json_path) load_result = load(transformation) print(load_result)
Após executar o arquivo main.py, os seus dados já deverão estar na tabela criada no BigQuery. Para verificar seus dados, acesse o painel da GCP e procure por BigQuery. Na aba “Explorer”, procure pelo dataset “Spotify_Data” e expanda-o. Ao expandi-lo, você deverá encontrar uma tabela com o nome “recently_played” contendo todas as músicas recentemente tocadas. Você pode realizar consultas em SQL no próprio terminal disponível na interface do BigQuery com o seguinte comando:
SELECT * FROM Spotify_Data.recently_played ORDER BY played_at ASC
5ª Passo: Automatizando o processo de ETL com o Cloud Composer
A ideia deste tópico é fazer o uso do Cloud Composer para automatizar a execução de todo o processo de ETL que realizamos até o momento.
Como citado anteriormente, o Cloud Composer é uma versão do Apache Airflow hospedada na GCP que serve para a orquestração de pipelines de dados (você pode acessar a sua documentação através deste link). Ele trabalha com o que chamamos de Grafos Acíclicos Dirigidos, ou DAGs (Directed Acyclic Graph). As DAGs são arquivos escritos em python que definem a sequência de execução de funções responsáveis por algum pipeline.
Caso tenha interesse em saber um pouco mais sobre o Airflow, recomendo uma série de artigos escritos pelo Yan Cescon Haeffner aqui no blog da ilegra. Comece por aqui: Apache Airflow: maestro de pipelines de tarefas agendadas.
+++ Ativar a API
No console da GCP, busque por “Composer”. Ao clicar nele, caso a API não esteja ativada, você encontrará uma tela de ativação. Clique em “Ativar” (vale lembrar que a utilização do Cloud Composer poderá acarretar em custos).
+++ Criar um novo ambiente
- No console do Composer, clique em “Create Environment” (ou “Criar ambiente”) e selecione Composer 1.
- Preencha com as seguintes informações:
- Nome: spotify-etl
- Local: us-east1 (procure deixar na mesma localização que o BigQuery)
- Node configuration:
- Contagem de nós: 3 (valor default)
- Zona: (valor default)
- Tipo de máquina: (valor default)
- Tamanho de disco: 20
- Escopos do OAuth: (valor default)
- Conta de Serviço: Selecione a sua conta de serviço
- Tags: spotify-etl
- Versão da imagem: composer-1.17.7-airflow-2.1.4
- Número de programadores: 1
- Versão do Python: 3
- Em seguida clique em “Criar”.
- Aguarde a criação do ambiente (pode levar alguns minutos).
+++ Criar DAG
Como já foi dito anteriormente, uma DAG é responsável pela definição e organização das tarefas que serão programadas e executadas. Para isso, precisamos construir um código em Python para a sua criação. Portanto, criaremos um arquivo chamado spotify_etl_dag.py com o código que pode ser encontrado neste link.
+++ Subir a DAG para o ambiente
Navegue até o painel de Ambientes do Cloud Composer e, na linha referente ao ambiente que foi criado anteriormente, clique no link da coluna “Pasta de DAGs” para que a plataforma te redirecione ao bucket de armazenamento de DAGs.
Estando no bucket de armazenamento de DAGs, faça upload do arquivo spotify_etl_dag.py que foi criado no passo anterior.
+++ Instalar as dependências no ambiente
Agora, para o correto funcionamento da nossa DAG, precisamos instalar algumas dependências no ambiente do airflow. Para isso, no painel de Ambiente do Cloud Composer, clique sobre o Nome do seu ambiente. A plataforma irá te redirecionar para uma página de Detalhes do Ambiente. Clique na TAB “PYPI PACKAGES” para incluir os pacotes necessários.
Já na TAB de Pacotes, clique em “EDITAR” e adicione o seguinte pacote:
- Nome do pacote: gcloud
- Extras e versão: ==0.18.3
- Clique em “SALVAR” e espere o ambiente ser atualizado (pode demorar alguns minutos).
+++ Definir a variável de ambiente contendo o Token do Spotify
No painel de Ambiente do Cloud Composer, clique sobre o link presente em “Servidor da Web do Airflow”. Ele irá te redirecionar para a interface de usuário do Airflow.
- Clique em “Admin” → “Variables”.
- Clique no sinal de “+” para adicionar uma nova variável.
- Preencha com as seguintes informações:
- Key: spotify_etl_dag_vars
- Val: {“spotify_secret”:”secret”} (troque a palavra “secret” pelo Token do Spotify e lembre-se da validade de 15 minutos deste token).
- Description: Spotify Secret Token
- Clique em “Save”.
Caso seja necessário alterar o token por conta da sua validade, você pode editar a variável sempre que precisar.
+++ Testando a DAG
Na tela inicial da interface do Airflow, você verá uma lista de DAGs. A nossa, “spotify_etl_dag” deverá estar presente nesta tela. Clique sobre o nome dela.
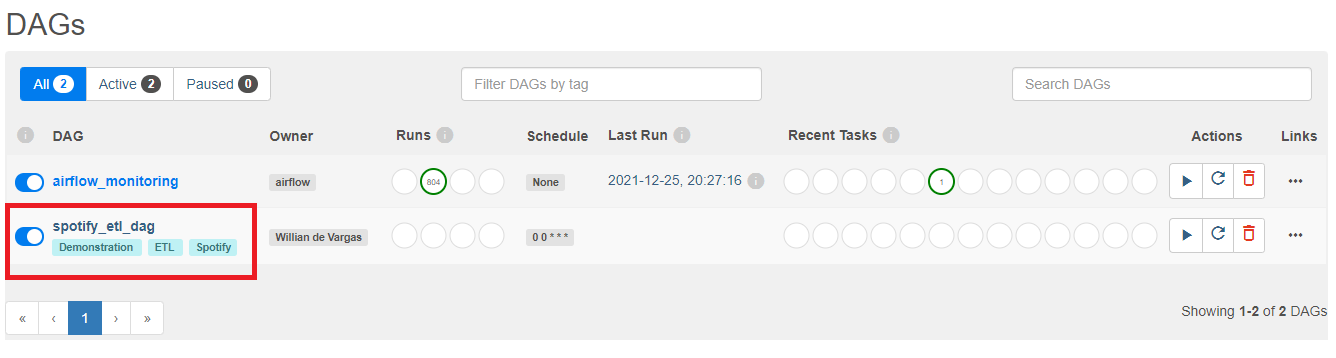
No código que escrevemos para a nossa DAG, definimos que a sua execução seria realizada todos os dias à meia-noite. No entanto, como este é um exemplo para fins demonstrativos, vamos forçar a execução da nossa DAG. Desta forma, conseguimos testar e verificar seu funcionamento.
Para isso, clique no símbolo de “Play”, presente no canto superior direito da tela e, em seguida, em “Trigger DAG”.
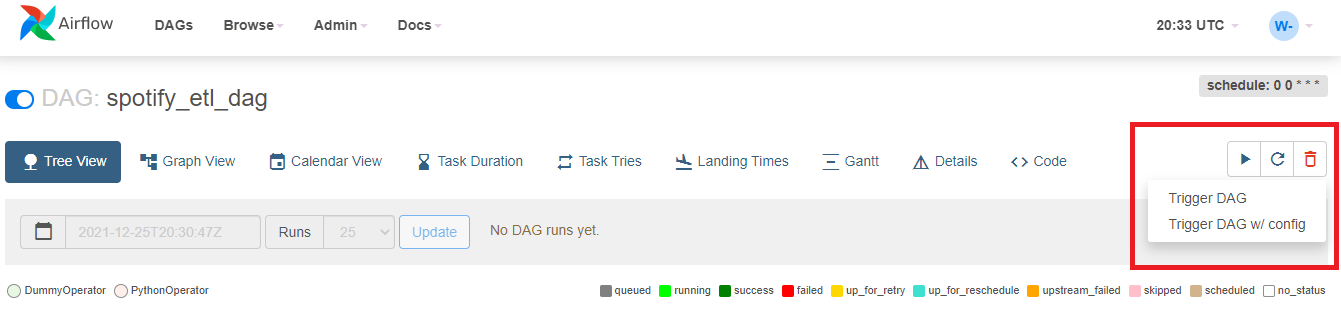
Agora, para uma melhor visualização, clique na TAB “Graph View” e espere até o fim da execução (você pode clicar no botão de refresh para atualizar os status conforme o processo for acontecendo). Ao final, todas as tasks devem estar contornadas por um verde escuro, que indica sucesso!
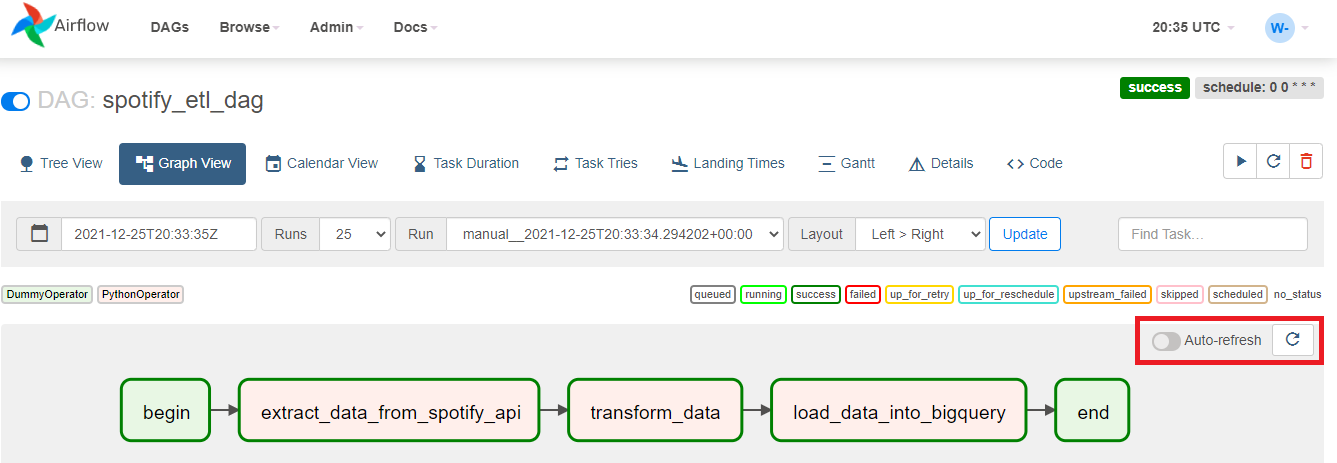
Com isso, finalizamos a nossa demonstração. Ao chegar até aqui, você aprendeu a criar um processo de ETL do zero e ainda aprendeu a automatizar a sua execução, tornando este processo totalmente executável em ambientes On Cloud. Utilizamos um exemplo bastante simples, que é o de recuperar músicas a partir do Spotify. Imagine, porém, que os processos que reproduzimos aqui são utilizados por milhares de empresas espalhadas pelo mundo, para recuperar e organizar dados diversos e em grandes quantidades.